The Flan Collection. Designing Data and Methods for Effective Instruction Tuning
Abstract
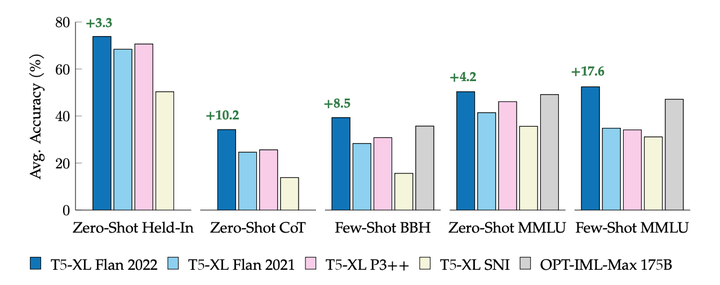
We study the design decisions of publicly available instruction tuning methods, and break down the development of Flan 2022 models (Chung et al., 2022). Through careful ablation studies on the Flan Collection of instruction tuning tasks and methods, we tease apart the effect of design decisions that enable FlanT5 to outperform prior work by 3-17%+ across evaluation settings. We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings. In further experiments, we show Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks—motivating instruction-tuned models as more computationallyefficient starting checkpoints for new tasks. Finally, to accelerate research on instruction tuning, we make the Flan 2022 collection of datasets, templates, and methods publicly available.
Shayne Longpre
AI Research Scientist
My research interests include AI/ML/NLP, and the governance of AI platforms.